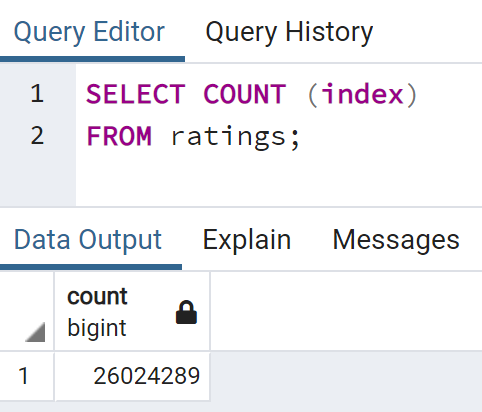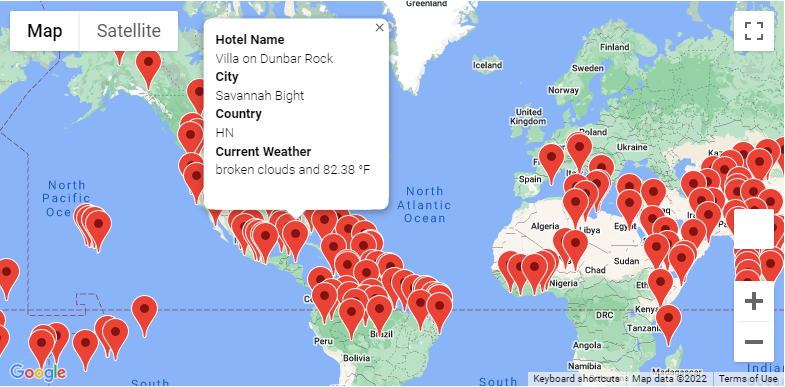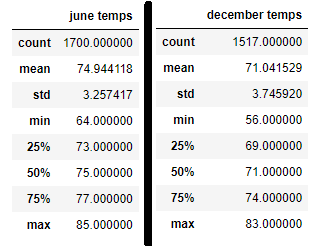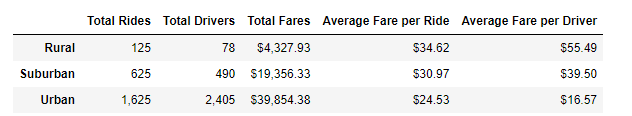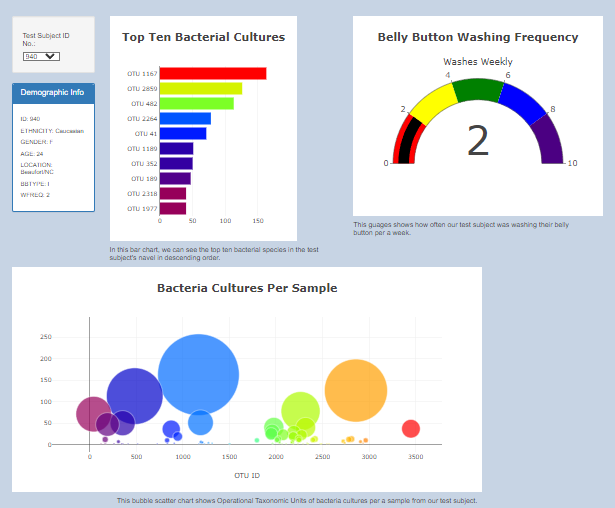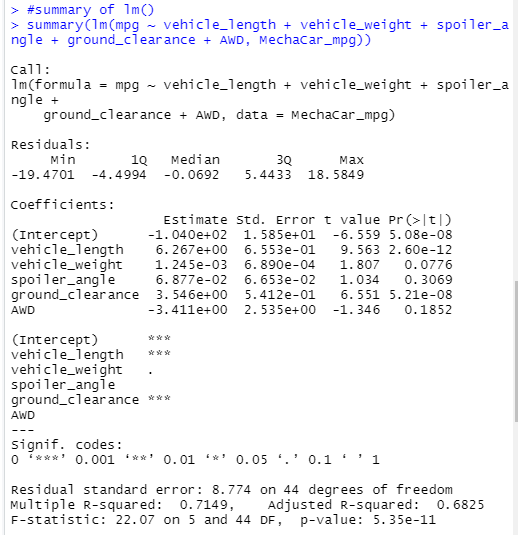
I'm Ariana!
Data Analyst | Nature Lover | Foodie
Result-driven data analyst with a background in the hospitality and service industries as well as skills in Excel, Word, VBA, Python, SQL, and Tableau with a certificate in the data analytics bootcamp with University of California San Diego. Creative critical thinker with attention to detail and organization who thrives in a team environment and takes the time to customize the experience to the customer. Enjoys skimming through data to track and find relevant trends to support making business-based decisions.With my ‘can do’ attitude, adaptability, and ability to trouble-shoot, I know that I can become a valuable asset to your team and take on any task at hand.